Someday I got interesting question in my job. Does SELECT query from multi-statement table valued function have impact on transaction log?
Because of result-set, there is a table variable declaration in multi-statement table valued function, we could expect the same behavior as described in post.
It would be interesting to make some tests, because I didn’t think about that simple select from function could affect transaction log of tempdb database. Results were surprising for me, follow reading this post, if you are insterested in. Just to remind, run bellow published scripts on testing environment only. I am using local installation of SQL on my laptop.
I would use similar approach as in post, In short.
- Clean up tempdb transaction log, and set the size of the log to the minimum
- Create multivalued function and select data from it
- Run simple select from the function
- In another query window run undocumented function sys.fn_dblog to get data from transaction log
- In another query window run allocation unit query extended to locking info (I will explain later)
- Check how tempdb transaction log file grew up
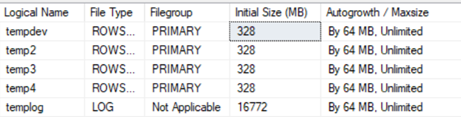
Firstly, set tempdb transaction log at the minimum size, to see if there is an impact on the transaction log. And call CHECKPOINT operation to clean-up transaction log. With the query bellow check list of allocation units with allocated pages in tempdb.
select request_type, request_mode,sa.total_pages,so.name, so.object_id, sp.index_id, sp.partition_id, sp.hobt_id, sa.allocation_unit_id, sa.type_desc , l.* FROM sys.objects so JOIN sys.partitions sp on so.object_id = sp.object_id JOIN sys.allocation_units sa on sa.container_id = sp.hobt_id LEFT JOIN sys.dm_tran_locks l ON so.object_id =l.resource_associated_entity_id WHERE total_pages >0
In my environment the query did not return any temporary tables with allocated pages. So we can start test.
Run script bellow to create testing function.
CREATE FUNCTION [dbo].[fn_GetData]()
RETURNS
@TableTest TABLE (id INT, testdata INT
)
AS
BEGIN
INSERT INTO @TableTest
SELECT a.object_id
, a.object_id
FROM sys.objects a
JOIN sys.objects b ON 1=1
JOIN sys.objects c ON 1=1
JOIN sys.objects d ON 1=1
JOIN sys.objects e ON 1=1
RETURN
END
GO
Query to get data from created function.
SELECT * FROM dbo.fn_GetData() ;
In another SQL query window run query returning allocation units, listed above. After querying allocation units from tempdb we can see that there is temporary table with allocated pages. Run query few times to see that count of allocated pages is increasing. See picture bellow.

Lets check tempdb transaction log file size. We can see that it was increased rapidly.
It is interesting that even when using simple SELECT from multi-statement table valued function, the tempdb transaction log can be affected. The Table variable declared for result-set inside the function is physically placed in tempdb. It is very similar behavior as in the post.
From sys.fn_dblog function we can see operations on Allocation unit (temporary table) we got from queries above.

This time I had problem with DBCC PAGE to check inserted data. I was not able to access data as in post. That was reason why I extended script querying allocation units to locking info, where you can see that temporary table has exclusive lock, so other processes cannot read data from it. In my previous post where I tested impact of Table variable on transaction log, there was BU (bulk load) lock mode set, so I was able to access data from sys.fn_dblog function.
Conclusion. Not only Table variable could impact transaction log, but multi-statement table valued function can affect it too. It is very interesting, and here raises another reason why you should be careful using these SQL features with respect to query performance. Both object types are physically created in tempdb database, not in memory. I found one difference between the table valued function and Table variable and it is lock escalation on these objects. While in case of Table variable, there was created temporary table in tempdb database with BU request mode, temporary table created by querying the multi-statement function was locked by X (exclusive lock). There would be probably more differrencies but maybe next time, and in another post.

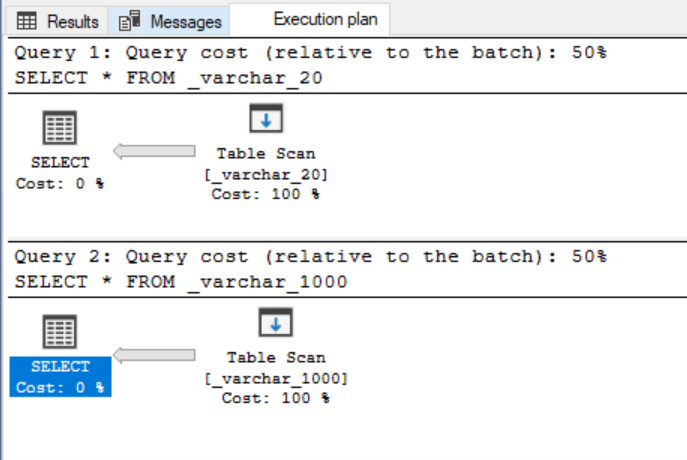
 The only one counter differs – Estimated row size but it has evidently no impact on query execution.
The only one counter differs – Estimated row size but it has evidently no impact on query execution.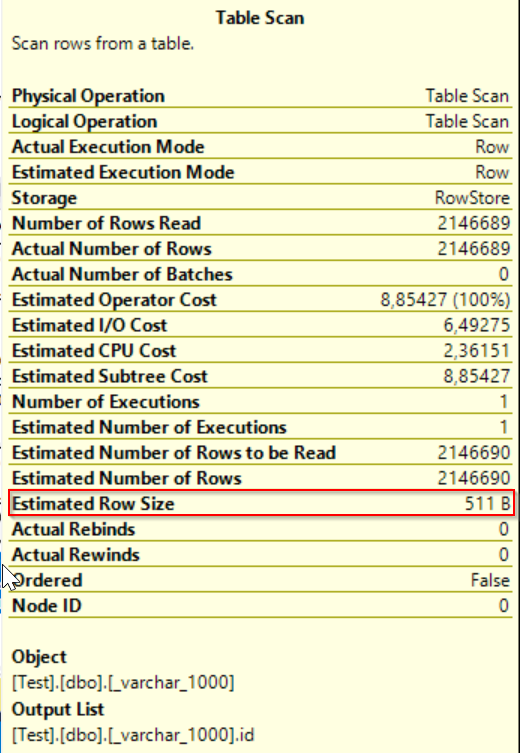
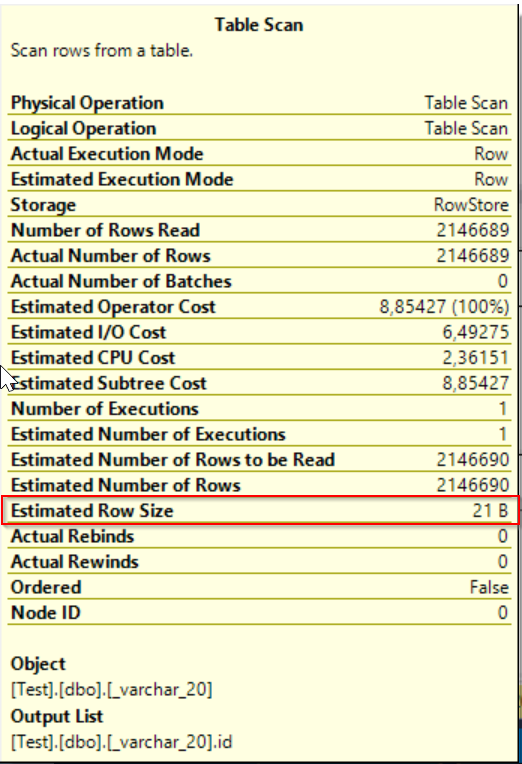

 Now we could say that sizing of
Now we could say that sizing of