To support my current database team with additional database skills I decided to start some series focused on BI area. This POST describes quick start with Analysis Services – Multidimensional Databases.
I already wrote post regarding Analysis Services (Create SSAS database) and its settings for multidimensional mode. What should be prepared in advance are some relation data (Adventure Works) and Data Tools studio supporting Analysis Services. You can find in my previous post.
GOAL:
Let’s make a simple cube including 1 measure and 2 dimensions.
In short:
Let’s create new project first – Multidimensional SSAS – Create Analysis Services Database
Create Data Sources
Create Data Source View
Create Dimensions
Create CUBE
Define measures
Create dimension relationships
Deploy solution to server
To be continued
Create Analysis Services Multidimensional and Data Mining project first.
New project
Define Data Sources. In our case, there is one Data Source to relation database. There could be defined more Data Sources from different connections. In Solution Explorer, right click on Data Sources section and click on New Data Source, define connection info in dialog box and confirm to create Data Source. Solution Explorer with defined Data Source should look like on picture bellow.
Solution explorer Data Source
As next step we must define objects for logical database model. Right click on Data Source Views section in Solution explorer and click on new Data Source Views and Wizard to create Data Source Views appears. Select Data Source in next window, Adventure Works DW in our case and you should see dialog with list of objects form your Data Source on left side. Choose objects for your data model and continue with next.
Data Source Wizard
After selection you should have chosen objects on the right side of Select Tables and Views window. We selected DimCustomer, FactInternetSales and DimDate in our case.
Data Source View Wizard
As last step name Data source View and Data Source View Wizard is finished.
Data Source View Wizard
In case you have relational layer defined with referential integrity, it should be transferred to the Data Source View. In case that primary and foreign keys are missing you can create logical relationships between tables in Data Source Views. It is possible to create more Data Source Views, in case you have lots of database objects it is good practice to split them according to their logical area.
When above mentioned steps are done you can see the same Solution Explorer as on picture bellow.
Solution explorer – Data Source View
Let’s check data model in Data Source Views on picture bellow. You can see that relationships were created according to relation layer by default.
Data Source View – model
To create our cube, we use Cube Wizard where measures and dimensions are defined.
Cube Wizard
To speed up our process, check Use existing tables. In next window, select Fact table to define measures. You can click on Suggest button to check it automatically (based on defined Data Source View).
Cube Wizard – measure
To finish Cube Wizard choose dimensions you use in the cube.
Cube Wizard – dimension
Now you should see created Cube and Dimensions in Solution explorer.
By double click on cube you see cube structure work space, with information regarding Measures, Dimensions, Data Source View etc.
Cube structure
On the top menu of the Cube Structure Workspace you can see menu yo can navigate to other sections, like Dimension usage, KPIs, Actions etc. What is interegsting now is to check Dimension usage you defined relationship between facts and dimensions. As you can see Cube Wizard did this task automatically.
Dimension usage
Now we can deploy our solution to server. Go to Project -> Properties see Configuraion dialog as on picture bellow. In Deployment section set Target Server and Database name. In other options you can set for example Processing Option to specify whether Analysis Services objects should be processed with deployment of the project. Leave Default in our case to Process cube after deployment.
Project Configuration – Deployment
After you confirm above mentoned seting go to solution explorer, right click on project and click on Deploy in context menu on picture bellow.
Deploy
After deployment we can Browse deployed and processed cube in Cube Browser – top right menu.
Cube Browser
As next steps we could extend dimensions by other attributes, try to create Hierarchy, add another dimension, etc. Lots of scenarios you can try now, but to be continued in next posts.
In this post I would like to continue with partitioning series. Previous post we created partitioned view and look how it looks like in execution plan. In this post we will create partitioned table.
In case of simple partitioned table, we will need to do following:
Create table
Create partitioning function
Create partitioned schema
Relationship between partitioned schema and the table
Let’s check created partition
Let’s verify partition query in execution plan
As in the partitioned view post there will be created 3 partitions within the same filegroup (without separated disks per partitioned). This solution will not profit from parallel reading from partitions separated on different disks. For simple demonstration it will fit.
Let’s create the table first
DROP TABLE [dbo].[PartitionedTable]
CREATE TABLE [dbo].[PartitionedTable] (id INT NOT NULL , booking_date DATE NOT NULL, data SYSNAME)
ALTER TABLE [dbo].[PartitionedTable] ADD PRIMARY KEY CLUSTERED ( [id] ASC, [booking_date] ASC)
Create partitioned function. It defines partition data according to following boundaries
The side of boundaries values is defined by LEFT or RIGHT key word.
CREATE PARTITION FUNCTION PartitionedFunction (DATE)
AS RANGE RIGHT FOR VALUES ('2019-10-01', '2019-11-01', '2019-12-01');
Create partition scheme to specify which partition of table or index belongs to which filegroup. All partitions are defined for Primary filegroup in our case.
CREATE PARTITION SCHEME PartitionedScheme
AS PARTITION PartitionedFunction ALL TO ([PRIMARY])
Now let’s create relationship between table and partitioned schema.
ALTER TABLE [dbo].[PartitionedTable] DROP CONSTRAINT PK_PartitionedTable__booking_date
ALTER TABLE [dbo].[PartitionedTable] ADD CONSTRAINT PK_PartitionedTable__booking_date PRIMARY KEY CLUSTERED ([booking_date] ASC) ON [PartitionedScheme]([booking_date])
Here we have few queries to check our partitioned objects.
Let’s check connection between partition schema and partitioned table.
SELECT *
FROM sys.tables AS t
JOIN sys.indexes AS i ON t.[object_id] = i.[object_id] AND i.[type] IN (0,1)
JOIN sys.partition_schemes ps ON i.data_space_id = ps.data_space_id
WHERE t.name = 'PartitionedTable';
View to check created partitions.
SELECT t.name AS TableName,
i.name AS IndexName,
p.partition_number,
p.partition_id,
i.data_space_id,
f.function_id,
f.type_desc,
r.boundary_id,
r.value AS BoundaryValue
FROM sys.tables AS t
JOIN sys.indexes AS i ON t.object_id = i.object_id
JOIN sys.partitions AS p ON i.object_id = p.object_id AND i.index_id = p.index_id
JOIN sys.partition_schemes AS s ON i.data_space_id = s.data_space_id
JOIN sys.partition_functions AS f ON s.function_id = f.function_id
LEFT JOIN sys.partition_range_values AS r ON f.function_id = r.function_id and r.boundary_id = p.partition_number
WHERE t.name = 'PartitionedTable' AND i.type <= 1
ORDER BY p.partition_number;
You can check partitioned column as well with following query.
SELECT
t.[object_id] AS ObjectID
, t.name AS TableName
, ic.column_id AS PartitioningColumnID
, c.name AS PartitioningColumnName
FROM sys.tables AS t
JOIN sys.indexes AS i ON t.[object_id] = i.[object_id] AND i.[type] <= 1 -- clustered index or a heap
JOIN sys.partition_schemes AS ps ON ps.data_space_id = i.data_space_id
JOIN sys.index_columns AS ic ON ic.[object_id] = i.[object_id] AND ic.index_id = i.index_id AND ic.partition_ordinal >= 1 -- because 0 = non-partitioning column
JOIN sys.columns AS c ON t.[object_id] = c.[object_id] AND ic.column_id = c.column_id
WHERE t.name = 'PartitionedTable'
;
Check Execution plan
If we run following query check execution plan how it is look like.
SELECT * FROM [dbo].[PartitionedTable] WHERE booking_date >=
CAST ('2019-11-01' AS DATE) AND booking_date <= CAST ('2019-11-30' AS DATE)
Execution plan – Actual partition count
We can see Actual Partition Count = 1 which is ok since we would like to get data just for one moth= one partition in our case.
Let’s notice RangePartitionNew function which contains ranges from all defined partitions. I would expect to see our predicate values, so why optimizer show this? The reason is that we use simple predicate in our query which leads to simple parametrization.
SELECT * FROM [dbo].[PartitionedTable] WHERE booking_date >= CAST ('2019-11-01' AS DATE) AND booking_date <= CAST ('2019-11-30' AS DATE)
Modify the query as follows
SELECT * FROM [dbo].[PartitionedTable] WHERE booking_date >= CAST ('2019-11-01' AS DATE) AND booking_date <= CAST ('2019-11-30' AS DATE) AND 1<>2.
It eliminates simple parametrization and we get in execution plan what we expected, see plan bellow.
Execution plan – Partition predicate
Let’s try to modify query now u can see in execution plan that partition count value is 2.
SELECT * FROM [dbo].[PartitionedTable] WHERE booking_date >= CAST ('2019-11-01' AS DATE) AND booking_date < CAST ('2019-12-01' AS DATE)
Execution plan – Actual Partition Count
It is important how the predicate is set. Since above mentioned query touches two partitions instead of 1.
That was very quick introduction to SQL Sever partitioning.
It would be nice to look at partitioning little bit deeper in one of my next post and try to compare some scenarios with partitioned views approach or how RangePartitionNew function works internally.
I was thinking about difference between INSERT and INSERT-EXEC statement from performance perspective since I saw lots of post announcing that you should avoid the second one mentioned (INSERT-EXEC). I decided to make few tests and look at this problematic from more angles to have better imagination about how these commands behave.
CREATE TABLE dbo.InsertTable1 (id INT , [data] VARCHAR(255))
CREATE TABLE dbo.InsertTable2 (id INT , [data] VARCHAR(255))
Create two persistent temporary tables we will fill inside procedures we create:
CREATE TABLE dbo.TempTable1 (id INT , [data] VARCHAR(255))
CREATE TABLE dbo.TempTable2 (id INT, [data] VARCHAR(255))
Create objects we use to test:
The first one is stored procedure inserting data to InsertTable1 table – insert statement is part of stored procedure definition.
CREATE PROCEDURE dbo.InsertData
AS
INSERT INTO dbo.TempTable1
SELECT TOP 100000 a.object_id,REPLICATE('a',10 ) a
FROM sys.objects a
JOIN sys.objects b ON 1=1
INSERT INTO dbo.TempTable2
SELECT TOP 100000 a.object_id,REPLICATE('a',10 ) a
FROM sys.objects a
JOIN sys.objects b ON 1=1
INSERT INTO dbo.InsertTable1
SELECT * FROM dbo.TempTable1
UNION ALL
SELECT * FROM dbo.TempTable2
The second one batch inserts data to InsertTable2 table – insert is realized by INSERT – EXEC statement.
EXEC ('INSERT INTO dbo.TempTable1 SELECT TOP 100000 a.object_id,REPLICATE('a',10 ) a
FROM sys.objects a
JOIN sys.objects b ON 1=1
INSERT INTO dbo.TempTable2
SELECT TOP 100000 a.object_id,REPLICATE('a',10 ) a
FROM sys.objects a
JOIN sys.objects b ON 1=1
INSERT INTO dbo.InsertTable1
SELECT * FROM dbo.TempTable1
UNION ALL
SELECT * FROM dbo.TempTable2
')
Execute satements to fill the data:
exec dbo.InsertData
INSERT EXEC ('…') /*put exec part above*/
Cleaning statements – call it before statements executions
Switch IO stats/processing time /actual execution plan in studio on. Or put following commands:
SET STATISTICS IO ON
SET SHOWPLAN_XML ON
SET STATISTICS TIME ON
Run following extended event with result to file.
CREATE EVENT SESSION GetRowsCount ON SERVER
ADD EVENT transaction_log
( ACTION (sqlserver.sql_text, sqlserver.tsql_stack, sqlserver.database_id,sqlserver.username)
)
,
ADD EVENT sql_transaction
( ACTION (sqlserver.sql_text, sqlserver.tsql_stack, sqlserver.database_id,sqlserver.username)
)
,
ADD EVENT sql_batch_completed
( ACTION (sqlserver.sql_text, sqlserver.tsql_stack, sqlserver.database_id,sqlserver.username)
)
ADD TARGET package0.event_file(
SET filename='C:\outputfile\outputfile2.xel')
ALTER EVENT SESSION GetRowsCount ON SERVER STATE = START
ALTER EVENT SESSION GetRowsCount ON SERVER STATE = STOP
DROP EVENT SESSION GetRowsCount ON SERVER
Statement completed event – counters
Queries touched 400000 rows. 100000 for each from the two temptables and 200000 for final insert. But in case of insert we can see from batch completed event that query touched 600000 instead of 400000. Look at table below to check other counters.
SELECT CAST (EVENT_data AS XML),
CAST (EVENT_data AS XML).value('(/event/data[@name="batch_text"])[1]','NVARCHAR(100)') AS batch_text,
CAST (EVENT_data AS XML).value('(/event/data[@name="duration"])[1]','NVARCHAR(100)') AS duration,
CAST (EVENT_data AS XML).value('(/event/data[@name="physical_reads"])[1]','NVARCHAR(100)') AS physical_reads,
CAST (EVENT_data AS XML).value('(/event/data[@name="logical_reads"])[1]','NVARCHAR(100)') AS logical_reads,
CASt
(EVENT_data AS
XML).value('(/event/data[@name="row_count"])[1]','NVARCHAR(100)')
AS row_count
FROM sys.fn_xe_file_target_read_file('C:\outputfile\outputfile1*.xel',
'C:\outputfile\outputfile1*.xem',
null,null) WHERE object_name = 'sql_batch_completed' ;
Counter
Insert
Insert – exec
Writes
1350
2194
Duration
9149345
11984022
Row count
400000
600000
Logical Reads
471973
962908
Physical Rads
662
1238
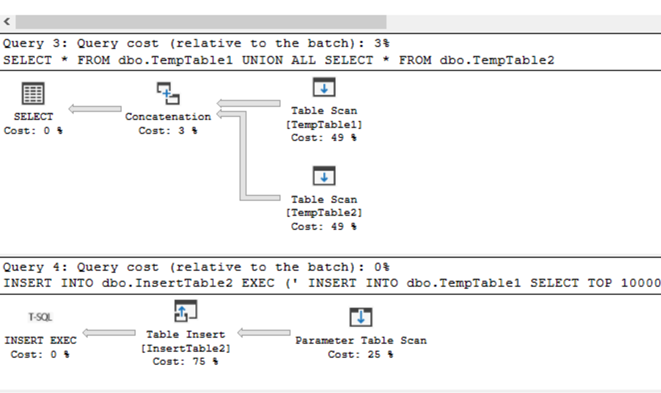
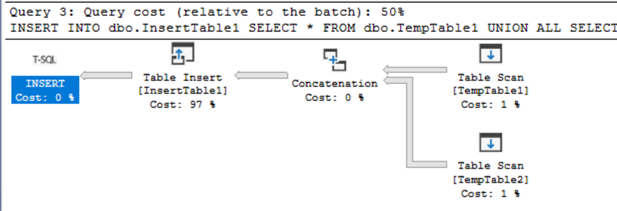
As you can see INSERT – EXEC statements consume more resources than normal insert on same set of data.
How it is possible than INSERT – EXEC generates additional 200000 row counts and finally touched 600000 rows and we made inserts with 400000 rows at total?
IO stats
Let’s check IO stats and execution plan to see the difference.
Worktable in IO stats
On picture above you can see that with INSERT-EXEC statement Worktable is created, means that insert-exec uses tempdb to store result- set before final insert. So, there we see that is an additional impact on tempdb and tempdb transaction log too.
Execution plan
Execution plan – INSERT EXEC
The difference in execution plan is as follow. With INSERT – EXEC you get two statements. The one for the result-set of EXEC and the second one for inserting the data.
Execution plan INSERT
Transaction log
Another perspective is the transaction scope behaviour. Let’s get data from transaction_log event to temporary tables first.
SELECT CAST (EVENT_data AS XML).value('(/event/data[@name="log_record_size"])[1]','INT') logsize,
CAST (EVENT_data AS XML).value('(/event/@timestamp)[1]','datetime2') timestamp,
CAST (EVENT_data AS XML).value('(/event/data[@name="transaction_start_time"])[1]','datetime2') date_time,
CAST (EVENT_data AS XML).value('(/event/data[@name="database_id"])[1]','INT') database_id,
CAST (EVENT_data AS XML).value('(/event/data[@name="transaction_id"])[1]','INT') transaction_id,
CAST (EVENT_data AS XML).value('(/event/action[@name="sql_text"])[1]','VARCHAR(1000)') sql_text ,
CAST (EVENT_data AS XML).value('(/event/data[@name="operation"])[1]','VARCHAR(1000)') operation
INTO #t1
FROM sys.fn_xe_file_target_read_file('C:\outputfile\outputfile1*.xel', 'C:\outputfile\outputfile1*.xem', null, null)
WHERE object_name = 'transaction_log' ;
SELECT CAST (EVENT_data AS XML).value('(/event/data[@name="log_record_size"])[1]','INT') logsize,
CAST (EVENT_data AS XML).value('(/event/@timestamp)[1]','datetime2') timestamp,
CAST (EVENT_data AS XML).value('(/event/data[@name="transaction_start_time"])[1]','datetime2') date_time,
CAST (EVENT_data AS XML).value('(/event/data[@name="database_id"])[1]','INT') database_id,
CAST (EVENT_data AS XML).value('(/event/data[@name="transaction_id"])[1]','INT') transaction_id,
CAST (EVENT_data AS XML).value('(/event/action[@name="sql_text"])[1]','VARCHAR(1000)') sql_text ,
CAST (EVENT_data AS XML).value('(/event/data[@name="operation"])[1]','VARCHAR(1000)') operation
INTO #t2
FROM sys.fn_xe_file_target_read_file('C:\outputfile\outputfile2*.xel', 'C:\outputfile\outputfile2*.xem', null, null)
WHERE object_name = 'transaction_log'
;
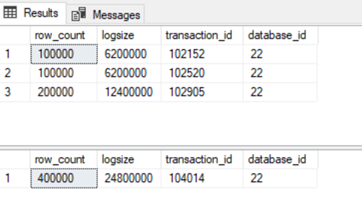
Comparing following query outputs, we can see that insert-exec is scoped by one transaction against multiple individual transactions with normal insert.
SELECT COUNT(1) row_count,SUM(logsize) logsize,transaction_id,database_id FROM #t1 WHERE operation = '2LOP_INSERT_ROWS' GROUP BY transaction_id ,database_id
SELECT COUNT(1) row_count,SUM(logsize) logsize,transaction_id,database_id FROM #t2 WHERE operation = '2LOP_INSERT_ROWS' GROUP BY transaction_id, database_id
Transaction log output
Transaction scope
In case of INSERT-EXEC statement it should rollback all insert statements inside of EXEC statement when error occurs, because INSERT – EXEC is scoped by one transaction. In case of individual transactions in stored procedure, each insert is taken like separate transaction, so rollbacked will be insert resulting with error. Let’s try:
Change type of inserting value to INT column in second insert.
INSERT INTO dbo.TempTable2
SELECT TOP 100000 REPLICATE('a',10 ) REPLICATE('a',10 ) a
FROM sys.objects a
JOIN sys.objects b ON 1=1
Run testing queries again. As you can see in case of INSERT-EXEC statement there are no rows inserted in tables since rollback appears.
Conclusion:
While INSERT-EXEC statement still takes place in some scenarios, you should be aware of mentioned circumstances.
NOTICE: I would like to check that transaction log of temporary database was filled with connection to the worktable created by INSERT-EXEC statement. But I cannot see any insert lop insert operation trough extended events in temporary database. I just see extent allocation
SELECT * FROM #t2 WHERE database_id = 2
If you have any idea whether worktables are logged and it is possible to trace them, please write a comment.